
【URLのみで簡単!】GPT CrawlerでMy GPTs用の入力ファイルを作成

新年、明けましておめでとうございます!
さて、新年早々、ChatGPTに課金してみました。
GPTからの応答が爆速になり、早く課金すれば良かったと思いました汗
GPT CrawlerでMy GPTs用の入力ファイルを簡単に作れるという
情報を得ましたので、早速試してみました!本記事はそのメモになります。
概要
「My GPTs」は、OpenAIが提供するカスタム言語モデル構築サービスです。
このサービスを利用することで、ユーザーは自分専用のGPTを構築し、
特定の用途やニーズに合わせてカスタマイズできます。
例えば、特定の業界や専門分野に特化したGPTを作成することが可能です。
GPT構築には、
まずユーザーが自分のデータを提供することから始まります。
そのデータは、
言語モデルが特定のトピックやスタイルを学習するのに使われます。
その後、OpenAIの技術を使用して、
そのデータに基づいてカスタムGPTがトレーニングされます。
最終的に、ユーザーは自分だけの言語モデルを使用して、
テキスト生成や他の言語関連タスクを実行できるようになります。
少ないファイル数で効率的に狙った回答をもらうには、
データを加工した上でアップロードする必要があります。
そのデータ準備に、GPT Crawlerを使うことで、
指定したURLの情報をクローリングして、
※インターネット上のウェブサイトを自動的に訪問し、情報を収集すること
My GPTsにアップロードするための加工されたデータを作成できます。
※オープンソース、MITライセンスなので、自由に改変可能。
使い方
GPT CrawlerにはDocker版もあったので、
今回はそれを使ってみました。
- リポジトリクローン
git clone https://github.com/builderio/gpt-crawler - Dockerfileのあるディレクトリに移動する
cd gpt-crawler/containerapp - config.tsに取り込みたいWebサイトのURLを記載する
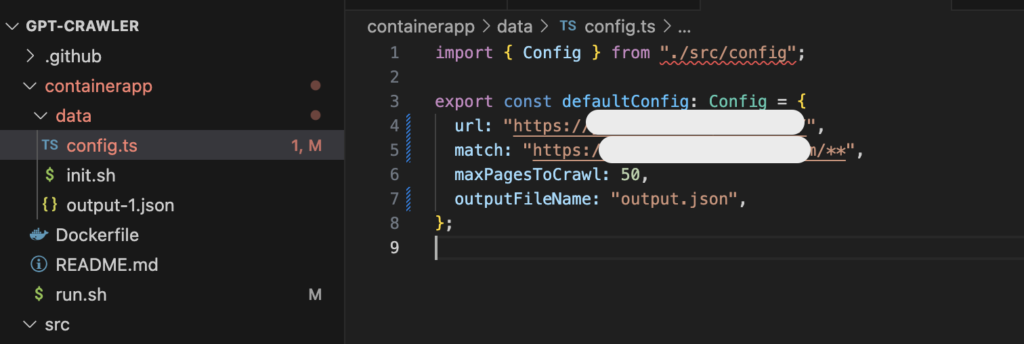

- run.shを実行する
./run.sh
Docker Buildして実行してくれるシェルがあるので
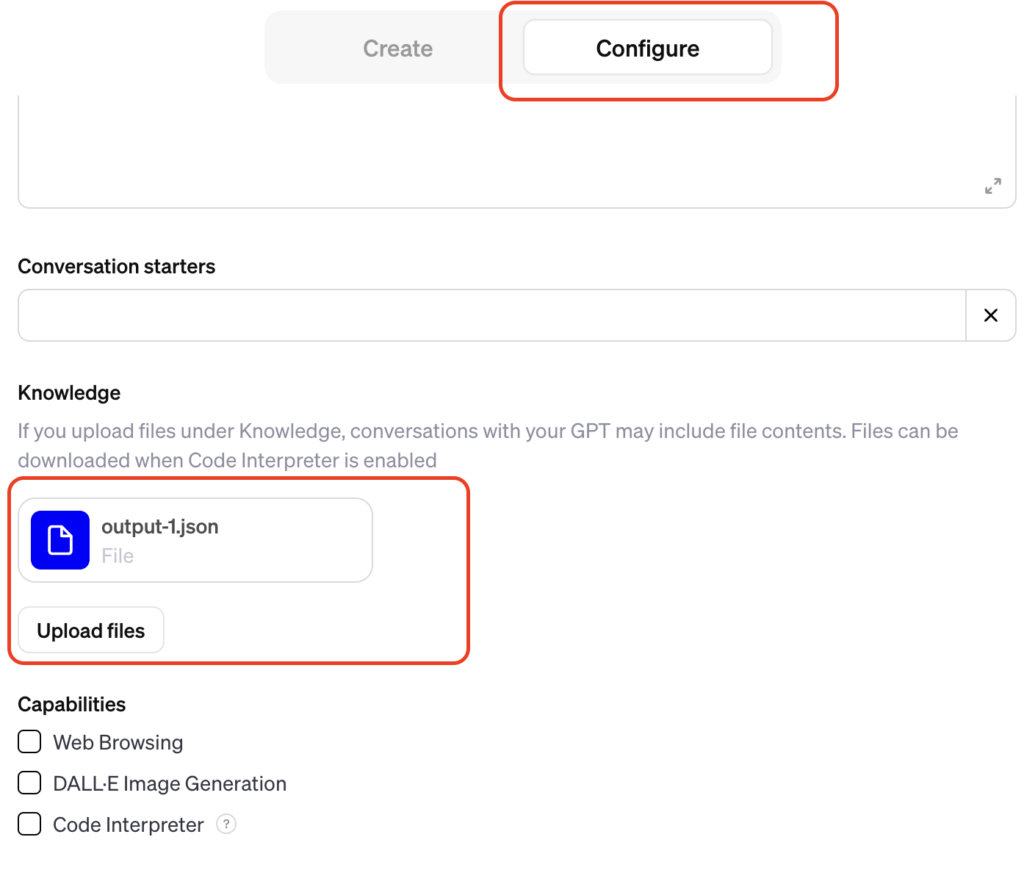
それを使います。便利! - 出力されたoutput-1.jsonをGPTsにアップロードする
- PreviewでGPTに質問してみる
今回は50ファイルくらいだったので、
正確な回答がきませんでしたが、
ファイル数を増やせばもっと有用な自分のGPTが作れそうです!
まとめ
本記事では、URLのみを使用して
GPTを作成するためのツール「GPT Crawler」について紹介しました。
GPT Crawlerは、指定したURLから情報をクローリングし、
GPTにアップロードするためのデータを加工するオープンソースツールです。
通常の使用方法にはNode.jsのインストール、リポジトリのクローニング、
必要なパッケージのインストールが含まれますが、Docker版を使えば
少し簡単に作業できますね!
ぜひ、皆さんも試してみてください!!






